I don't know if there's a specific channel for requests. I just opened a ticket in General Inquiry, but essentially what I feel could improve both SoundGym and ToneGym is this
I think the games are pretty good overall, but what would make them better would be a message to point out what you did wrong or right after you get an answer wrong or right.
For example, on the Compressionist game it would be immensely helpful if, after I got an answer wrong, I could see exactly why the other answer was in fact more compressed like Notice that the kick has a smoother sound on the right answer or something like this. It could be a message that only appears when you hit the C key to compare the answers. I don't know
Help me get this message to the people in charge hahahaha
hello, I know it's possible to buy full tracks for training in artists sounds, but is there anyway to buy different isolated tracks? that would be amazing. Thank you so much!
Dream Theater's Mike Mangini played the drums, now watch a top engineer build the full mix from scratch. This is the kind of session that changes how you think about drum processing 🥁🎛️
We use cookies to improve your experience. Essential cookies keep the site running. We also use optional cookies to enhance performance, analyze traffic, and personalize ads. By clicking “Accept”, you agree to the use of all cookies.




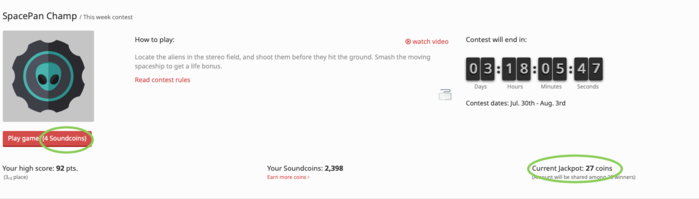










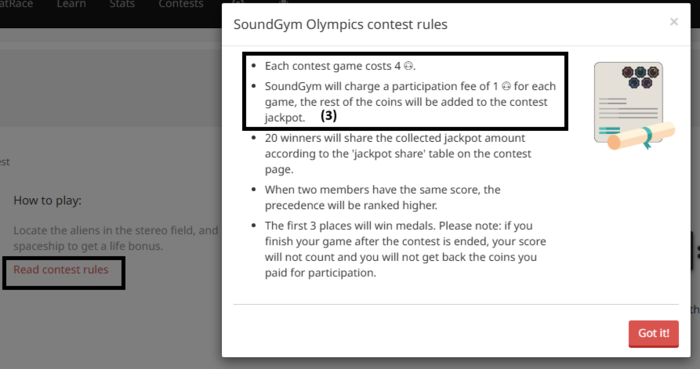











Aug 01
Aug 01
Aug 03, 07:58